
In today’s ultra-competitive digital landscape, Artificial Intelligence (AI) is vital in delivering smart and adaptive solutions. A key aspect of maximizing AI’s potential lies in choosing between AI model training (also known as fine-tuning) and prompt engineering. This critical decision can have far-reaching implications on your project’s performance, budget, and time to market.
Are you looking to build a sentiment analysis tool for your restaurant management software? Perhaps a chatbot for lead qualification? Or maybe a knowledgebase bot integrated into your Confluence platform? The article will dive deep into each approach, debunk popular misconceptions, and provide real-world examples to guide your decision-making process.
On your journey to create an AI-enabled business, we invite you to simplify your decision-making process by taking a closer look at fine-tuning, prompt engineering, plug-ins, and embeddings and understand when and why to use each in your AI project. By the end, you’ll have a clearer perspective on aligning your AI strategy with your business needs.
Understanding AI Model Training and Fine-tuning
What is AI model training?
Fine-tuning is the process of updating a pre-trained language model’s parameters to adapt it for a specific task. It’s more like calibrating a high-performance machine rather than building it from scratch.
To shed light on the mechanics, let’s delve a little deeper. Imagine you have an AI model that can distinguish between images of cats and dogs – a classic use-case scenario. This capacity is achieved by initially training the AI model with thousands of labeled images. Through studying these examples, the model learns the unique characteristics or ‘features’ that define each category. Therefore, it can confidently categorize it as a cat or dog based on these learned features when presented with an unfamiliar image.
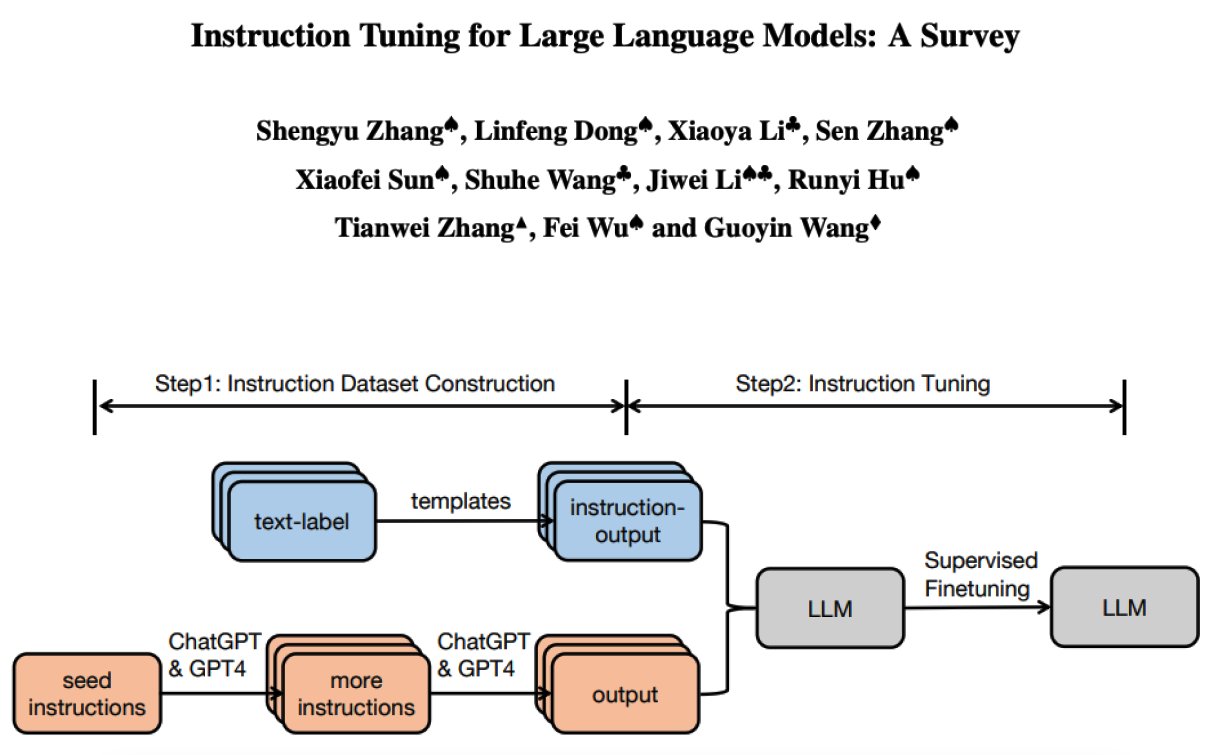
Fine-tuning Open AI Cost Structure
Now, let’s talk numbers. The cost of fine-tuning an AI model, according to OpenAI, can be subdivided into training and usage costs. For their fine-tuning service for GPT-3.5 Turbo, the costs are as follows:
Consider that the GPT-3.5-turbo fine-tuning job with a training file of approximately 75,000 words (100,000 tokens) would cost around $2.40. The update from OpenAI shows that GPT-4 will be available for fine-tuning in the coming fall, bringing even greater customized capabilities to AI developers.
- Initial Training: $0.008 / 1K Tokens
- Usage Input: $0.012 / 1K Tokens
- Usage Output: $0.016 / 1K Tokens
Key Application Areas for fine-tuning AI model
- Categorization: Segregate data into meaningful categories.
- Example: Spam vs. Non-spam in email filtering.
- Filters: Apply additional conditions to narrow down search or selection.
- Example: Recommending books based on user history.
The Limitation of Fine-tuning
However, the common misconception is that this fine-tuning mechanism can be universally applied, particularly to tasks requiring an understanding of unique, domain-specific information. If you were to show the AI model a single document highlighting a company’s organizational structure and anticipate it to comprehend the underlying structure and operations, you would, unfortunately, be disappointed. It simply doesn’t work that way. Fine-tuning and initial training are more about a focused effort, presenting many examples to help the AI model label unseen instances.
Myth-busting: Fine-tuning will not enable a model to understand a company’s org structure based on a single document.
Cost-Benefit Analysis
- GPT-3.5 Turbo vs. GPT-4: Fine-tuning a GPT-3.5 Turbo can match or outperform GPT-4 on specific tasks at about 50x lower cost.
- Fine-tuning Adds Cost: Expect an 8x cost increase when fine-tuning GPT-3.5 Turbo and training costs.
Pragmatic DLT’s Stand: Given the advancements in the field, building a new model from scratch is rarely advisable. Starting with third-party large language models (LLM) like OpenAI or HuggingFace is quicker and more cost-effective.
Fine-tuning is a potent tool when you have a specific, well-defined problem and a dataset to tune the model. It comes at a higher cost but can yield high value when applied to the right kind of tasks.
The Power of Prompt Engineering
Prompt engineering represents an alternative path when considering language model applications for your business. It delivers high value with relatively lower cost implications. Let’s dissect what it entails and the unique benefits it offers:
What is Prompt Engineering?
Contrary to the often misconstrued perception, prompt engineering does not involve a hefty round of model training. Instead, it capitalizes on temporary learning during the phase known as “inference”. In simpler terms, this process involves feeding the language model crucial pieces of information (or ‘prompts’) at the time of use that guide its responses.
This can be anything from finely chosen phrases to specific facts, essentially serving as a real-time nudge influencing the model’s prediction. Two main areas where prompt engineering shines are delivering live information and adapting your organization’s unique facts.
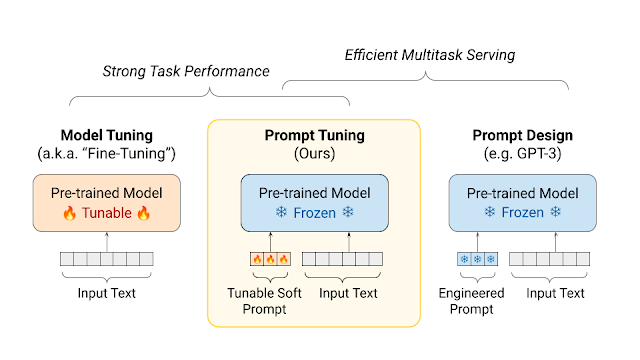
Key Characteristics
- Temporary Learning: The changes are not saved in the model.
- Application Areas: Suitable for real-time tasks like fetching live information or using custom facts known as embeddings.
- Quick Iteration: The approach offers a short development cycle, ideal for testing or adapting to fast-changing needs.
Cost and Efficiency
- From our experience, simple commands matter. Appending “Be Concise” to your prompt can result in 40-90% cost savings.
- The early stages of projects often benefit from a shorter iteration cycle for testing different instructions.
Why Choose Prompt Engineering?
The primary advantage of prompt engineering is its remarkable ability to fine-tune system responses without requiring computationally expensive model re-training. Here are a few compelling reasons to opt for such an approach:
- Flexibility: It provides a useful medium for quickly experimenting with different instructions. For example, you can try various prompts with your AI before deciding on the most effective one that fetches the desired results.
- Cost-efficiency: While a fine-tuned model on OpenAI costs around 8 times more than the base model, modifying the prompt can achieve a similar impact at a mere fraction of the cost. Thus, your operating expenses can be substantially reduced.
- Shorter Iteration Cycle: In the beginning stages of a project, prompt engineering can be a more efficient strategy due to its shorter iteration cycle. This is advantageous for projects that are still being defined and can benefit from quick adjustments.
Real-world Application: A Qualification Chatbot
Take, for instance, the use of a qualification chatbot to aid a sales team in lead sorting. Here, prompt engineering can instruct the model to respond to a variety of potential lead inquiries without requiring a full-scale model re-training.
The chatbot can be promptly engineered to filter inquiries based on predefined sales criteria and assist with lead qualifications. Thus, not only can the sales team answer customer queries swiftly, but they can also target potential leads with a higher precision.
In conclusion, prompt engineering is a smart, effective, and cost-efficient approach to building AI systems that deliver real-world impact. Its versatile application lends it an edge over the more tedious and often expensive fine-tuning process, especially during the initial stages of a project. As with many strategic choices, the balance lies in understanding when to employ which strategy.
When to Use Prompt Engineering
- Quick Prototyping: Early project stages often require fast iterations, making prompt engineering a go-to solution.
- Task-Specific Utility: For tasks that don’t warrant the investment in fine-tuning, such as one-off queries or low-frequency tasks.
- Cost-Effective: Given the 8x cost increase when using a fine-tuned model, prompt engineering can be a budget-friendly alternative.
You might also like
generative-ai
Creative Text Tools for AI startup developers
As businesses continue to adopt new technologies, the demand for artificial intelligence (AI) consultants has grown. These consultants provide guidance and support to businesses looking to implement AI solutions that can improve efficiency, enhance customer experiences, and drive revenue growth. At the same time, the rise of creative text tools such as GPT-3 has opened […]
The Utility of Plug-ins and Embeddings
Understanding the effective use of plug-ins and embeddings is key in AI development, particularly when working with Language Learning Models (LLMs) like OpenAI’s ChatGPT.
AI model Plug-ins: In essence, plug-ins extend the functionality of your AI, allowing it to integrate with SaaS offerings or other built-in services. For instance, a chatbot can be further developed to integrate with your company’s database to create a richer and more customizable user experience.
Consider the plugins of customer relationship management (CRM) software. A chatbot, enhanced by a CRM plug-in, can recognize specific customer queries and leverage customer data from the CRM to answer them more effectively. This makes it possible to provide more personalized customer experiences without the added cost and time of coding these integrations into your AI model from the ground up.
AI model Embeddings also lend themselves to extending an AI’s capabilities, albeit in a different way to plug-ins. They essentially distill the specific knowledge from your database and supply it to the AI through a series of prompts. This facilitates a dialogue where AI could provide the most pertinent response based on an individual user’s behavior, historical actions, or preferences.
For example, a customer-facing chatbot integrated with your product documentation can provide detailed information and resolve specific product-related queries without human intervention. Equipping your app with your database’s specific knowledge will allow the AI to make accurate recommendations and assist customers in a more personalized and knowledgeable manner.
OpenAI recently revealed that asking a question in a neural information retrieval system that uses embeddings is around 5x cheaper than GPT-3.5 Turbo. When compared to GPT-4, there’s an impressive 250x difference. Thus, it’s becoming clear that leveraging embeddings can lead to substantial savings and enhance the overall performance of AI systems.
In effect, plug-ins and embeddings provide an avenue to customize AI models for specific requirements without the high cost and complexity of building a new model from scratch. However, companies should consider the overall business goals, available resources, and the degree of customization required when deciding between plug-ins, embeddings, fine-tuning, or even prompt engineering for their AI development activities.
When to Use Plug-ins
- Low Complexity: When your project doesn’t demand a deep understanding or customization of the AI model.
- Fast Deployment: Ideal for projects with tight deadlines.
- Third-Party Reliance: When your project relies heavily on third-party services.
When to Use Database Embeddings
- High Specialization: When your project requires the AI to understand specific terminology or data structures.
- Data Security: Better control over data, especially if stored on-premises.
- Long-term Value: As your database grows, so does the AI model’s efficiency.
Deep Dive: The Fine-tuning Procedure for AI Models
Fine-tuning AI models plays a vital role in AI utilization within businesses. This process involves tailoring a pre-trained AI model to tackle specific issues or cater to unique needs.
To ease comprehension, let’s explore a real-life example – ORTY, a restaurant management system. This system leveraged fine-tuning to perform sentiment analysis on popular review websites, giving restaurant owners succinct overviews of the prevailing sentiments attached to their businesses. A simple task on the surface, but one with far-reaching implications, especially when considering the algorithm’s multi-faceted functionality.
To accomplish this task, the Pragmatic DLT team initially employed a basic classification model. They then utilized GPT-3.5 Turbo to fine-tune this model, leveraging its categorization and filtering capabilities. The objective here was twofold: to sift through thousands of reviews, accurately parse reviewer sentiments, and categorize these sentiments for easy digestion by restaurant owners.
The fine-tuning process commenced with feeding the AI model thousands of labeled examples. These examples ranged from purely positive reviews to a mix of positive, neutral, and negative feedback. Following this ‘feeding’ process, the AI model was tasked with labeling previously unseen examples, guided by the distinguishing features it had learned.
The results? Quite impressive. The fine-tuned AI model accurately distinguished and appropriately categorizes sentiments within restaurant reviews. This effectively enables the ORTY system to deliver an aggregated and easy-to-understand sentiment overview to restaurant owners.
So, how long did it take to achieve these results? It took approximately two months, from the onset of the fine-tuning process to getting the application fully ready. Restaurant owners expressed high satisfaction levels with the service provided by ORTY, further emphasizing the effectiveness and practical application of fine-tuning.
- AI model Fine-tuning Project details:
- Objective: The prime aim was to classify reviews into positive, neutral, or negative categories.
- Approach: The team fine-tuned a classification model derived from GPT-3.5 Turbo.
- The fine-tuning process: The team fed the AI model with thousands of labeled examples, which included a range of positive reviews and a mix of positive, neutral, and negative sentiments. The AI model then labeled previously unseen examples based on distinguishing features learned.
- Project costs & duration:
- Fine-tuning and iterations: It took six weeks for the classification model to be fine-tuned using GPT-3.5 Turbo.
- Testing and Deployment: This phase lasted for about two weeks.
- Total: The entirety of the fine-tuning endeavor spanned ten weeks.
- Training cost: The token-based training cost was $0.008 per 1,000 tokens.
- Usage cost: The usage cost was $0.012 per 1,000 tokens for input and $0.016 per 1,000 tokens for output.
The final product achieved remarkable results in distinguishing and categorizing sentiments within restaurant reviews. This fine-tuned AI model considerably simplified the ORTY system’s task and gave restaurant owners an easy-to-digest sentiment overview. This successful endeavor boosted customer satisfaction levels and increased user engagement by 20%, serving as a testament to the fine-tuning effectiveness.
It’s noteworthy to mention that a fine-tuned model’s serving cost is about six times more than the base model on OpenAI. However, fine-tuning provides superior performance levels without requiring a substantial financial outlay.
Invalid post URL.The decision to fine-tune an AI model relies heavily on task-specific requirements, the task complexity, and the expected return on investment. Without a labeled review dataset, the result might not be feasible, and in such a scenario, prompting makes a better option.
Deep Dive: The Prompt Engineering Route
Prompt engineering aims for a more dynamic and flexible AI, capitalizing on temporary learning during immediate inference. This stands in contrast to fine-tuning, which relies on a more persistent form of learning from a large corpus.
When considering a project that requires quick iterations and changes throughout its development process, prompt engineering typically wins out. A clear testimony of this is a Pragmatic DLT case with one of their customers, who demanded a qualification chatbot for sales lead generation.
This client was tirelessly looking for an AI solution to swiftly adapt to their dynamic and evolving sales environment. The aim was to develop an AI chatbot to qualify leads, saving time for their sales team and providing a seamless customer experience.
Prompt engineering stood out as the approach for a few key reasons:
- Shorter iteration cycle: With prompt engineering, the project could swiftly iterate through various instructions and make changes on the fly without extensively retraining the model.
- Cost and time-effective: Prompt engineering could speed up the development process since it didn’t require extensive fine-tuning. This factor dramatically increased its cost-effectiveness as opposed to rigorous model training.
- Real-time adjustments: It allowed the ability to adjust responses based on real-time data, ensuring the chatbot could adapt to different customers’ contexts.
Fast-forward to the end of the project, and the client was enormously satisfied. In terms of project duration, the whole process took about two months, which was significantly less than the time required for building and fine-tuning an AI model from scratch. The resulting chatbot was able to efficiently handle sales lead qualification with precision and context awareness.
- Prompt engineering Project cost & duration
- Objective: To quickly and accurately qualify sales leads based on set parameters.
- Method: Employed prompt engineering to tailor ChatGPT on custom data.
- Duration: The project was completed in 4 weeks.
- Satisfaction: The customer recorded a 100% job satisfaction rate.
This pragmatic approach illustrates the power and flexibility of prompt engineering. When AI API needs to be customized to fit specific interactive responses and infused with agility, prompt engineering provides a profitable, swift, and effective solution to consider. However, it is important to note that the choice entirely depends on the type and purpose of the project undertaken.
Deep Dive: Embedding Data into AI
When deploying AI applications, particularly Natural Language Processing applications powered by language models like ChatGPT, data embeddings are an effective method to provide specific or proprietary knowledge. In this context, embedding data goes beyond merely training the model with large volumes of general-purpose text. It equips the application with the specific knowledge from your database, thus significantly improving the relevancy of the AI application to your specific field or industry.
Applications of Data Embedding
- Knowledge Management Systems
- Real-time Analytics Dashboards
- Customer Support Platforms
- Personalized Content Discovery
A pivotal example of this use case is the Get Report’s Copilot for Confluence – a chatbot deeply integrated into the Confluence knowledgebase. Serving hundreds of enterprise companies, this chatbot enables employees to use ChatGPT in the context of their internal database effectively.
In Get Report’s Copilot application, ChatGPT is trained on general web text and equipped with data embedded directly from the company’s Confluence knowledgebase. This ensures that the chatbot’s responses are not just general but purposefully relevant, providing employees with the precise information they need within the context of their company’s specific operations.
The process of achieving this contextual knowledge involves a series of prompts passed to the AI, which provide it with the vital context required to generate suitable responses. This method of equipping AI with proprietary information from a user’s database has proven to be substantially efficient and versatile.
Regarding project length, the process of data embedding for this kind of application usually takes 3 to 6 months to fully implement, depending on the size and complexity of your database. Feedback from clients who have adopted Get Report’s Copilot application indicates high satisfaction rates, primarily due to the impressive increase in operational efficiency and the resultant cost savings achieved by leveraging AI in this manner.
- Data Embedding Project cost & duration:
- A chatbot integrated into Confluence knowledge bases, utilized by hundreds of enterprise companies.
- Allows for real-time context-sensitive queries using ChatGPT, guided by the company’s internal database.
- Duration of Project:
- Initial prototype: 2 months
- Full-scale Deployment: 6 months
- Customer Satisfaction:
- The chatbot received a 95% job satisfaction rate based on internal surveys.
- A notable improvement in information retrieval time for employees.
- Why Data Embedding Was Ideal:
- Real-time updates from Confluence databases were crucial.
- Cost-effective compared to alternative methods.
Limitations
- Latency can be an issue for real-time applications.
- Requires ongoing maintenance to ensure data integrity.
Takeaways
- Data embedding is highly effective for context-sensitive applications.
- Substantial cost benefits but comes with its own set of challenges, such as latency and maintenance.
Embedding data into AI applications isn’t just about improving results; it’s also about cost efficiency. Consider a scenario where you’re using language models for information retrieval. Asking “What is the capital of Delaware?” in a neural information retrieval system costs around 5 times less than with GPT-3.5-Turbo. If you’re comparing against GPT-4? There’s a massive difference of 250 times in cost! Thus, data embedding allows businesses to access powerful AI capabilities while maintaining control over cost.
By integrating real-time databases through data embedding, AI models like ChatGPT can serve highly specific queries tailored to the enterprise’s needs. Companies like Get Report have successfully leveraged this approach, making it a viable strategy for deploying AI in a context-rich environment.
Comparative Analysis
It’s essential to compare these approaches head-to-head to make an informed decision about whether to use AI model fine-tuning, prompt engineering, or plug-ins and embeddings.
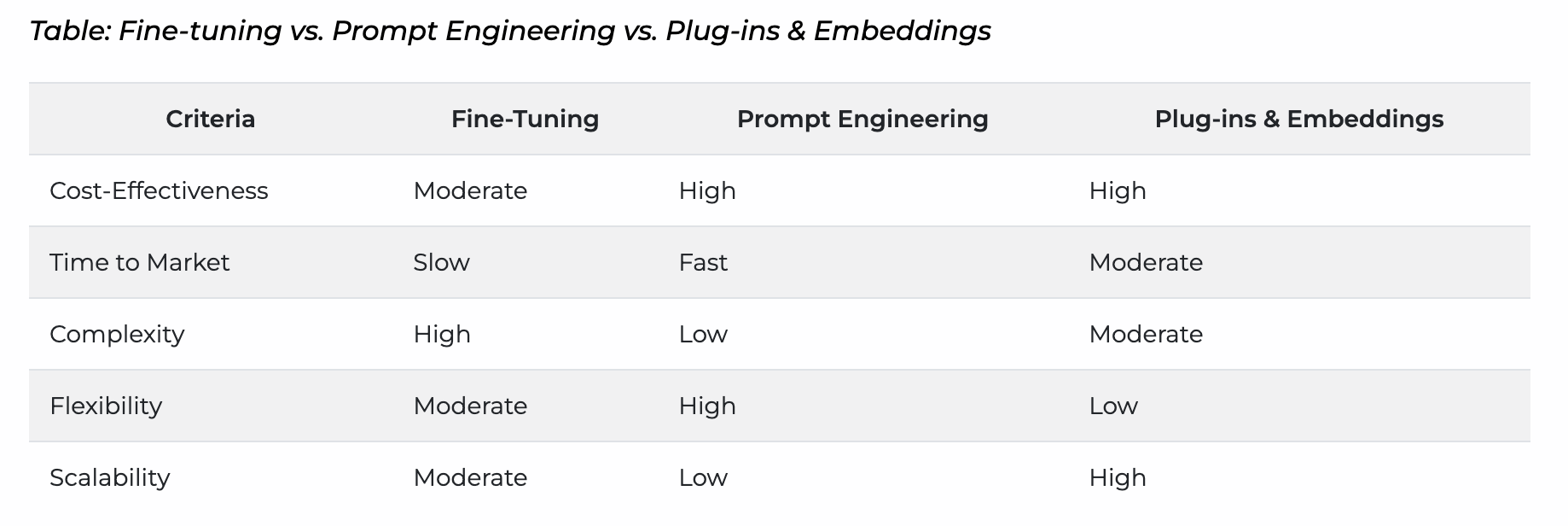
Criteria Explained
- Cost-Effectiveness
- Fine-Tuning: Initial costs are high due to training; usage also has costs ($0.016 / 1K Tokens).
- Prompt Engineering: Mostly cost-effective, especially if you just append “Be Concise” to your prompt.
- Plug-ins & Embeddings: One-time setup, especially cost-effective for data-centric applications.
- Time to Market
- Fine-Tuning: Requires significant time for training and iterations.
- Prompt Engineering: Quick to implement, shorter iteration cycles.
- Plug-ins & Embeddings: Moderate time required for setting up and testing.
- Complexity
- Fine-Tuning: Involves training on thousands of labeled examples.
- Prompt Engineering: Quick and straightforward; no formal training required.
- Plug-ins & Embeddings: Moderate setup time, needs proper data structuring.
- Flexibility
- Fine-Tuning: Limited by the quality and quantity of labeled data.
- Prompt Engineering: Highly flexible; good for rapid iterations.
- Plug-ins & Embeddings: Limited to database or SaaS service capabilities.
- Scalability
- Fine-tuning: Scales well but increases cost linearly.
- Prompt Engineering: Not ideal for scaling; redundant token costs pile up.
- Plug-ins & Embeddings: Highly scalable, especially if integrated with robust SaaS services.
Based on these criteria, you can select the most appropriate method that aligns with your business needs, time constraints, and budget.
Summary of Approaches and Recommendations Based on Specific Business Needs
When deciding on the optimal route for your AI projects, understanding the trade-offs associated with each approach is key. Typically, this centers around three interconnected concerns: costs, capabilities, and time to market. This is a usual approach Top AI Consultants like Pragmatic DLT suggest:
1. Building a New AI Model from Scratch
Though possible, this option is often most costly and time-intensive. As Pragmatic DLT, a seasoned AI consulting company, advises, building a new model generally outweighs reasonable investment parameters given the current advancements in Large Language Models (LLM) such as OpenAI or HuggingFace. These third-party models already offer highly competitive conversation and analytical capabilities that a newly built model might struggle to match. In light of this, dedicating resources to creating a new AI model from the ground up can be considered impractical and inefficient.
2. Leveraging Third-Party Large Language Models (LLMs) with a Focus on Prompt Engineering
The recommended first step is to start with a third-party LLM like OpenAI or HuggingFace. These models can be utilized to perform tasks based on your existing knowledge base, and custom algorithms can be engineered for responses via LangChain/OpenAI functions. This approach enables the creation of a production-ready, quick, and cost-effective application. It provides an early-to-market solution and allows you to start providing value to stakeholders and customers at an accelerated pace.
3. Fine-tuning of Base Open Source Models
Once your initial AI solution is in place and performing well, further iterations can involve fine-tuning opensource models. This stage typically involves a more research-oriented approach. However, once completed, you will have a proprietary model enriched with intellectual property (IP). This fine-tuned AI could be a significant asset for further fundraising and increasing your company’s competitive edge despite the potentially lengthy timeline to achieve it.
Understanding where your business stands on the axes of time, budget, and technical prowess is pertinent in deciding which approach to take. The most recommended path is pragmatic, starting with prompt engineering powered by third-party LLMs and slowly iterating towards fine-tuning open-source models. It balances costs, capabilities, and time to market, ensuring your AI investment yields maximum returns.





